Learning to Guide Online Multi-Contact Receding Horizon Planning
This article has been accepted on IROS 2022
Tags:
publications
HQP
Abstact
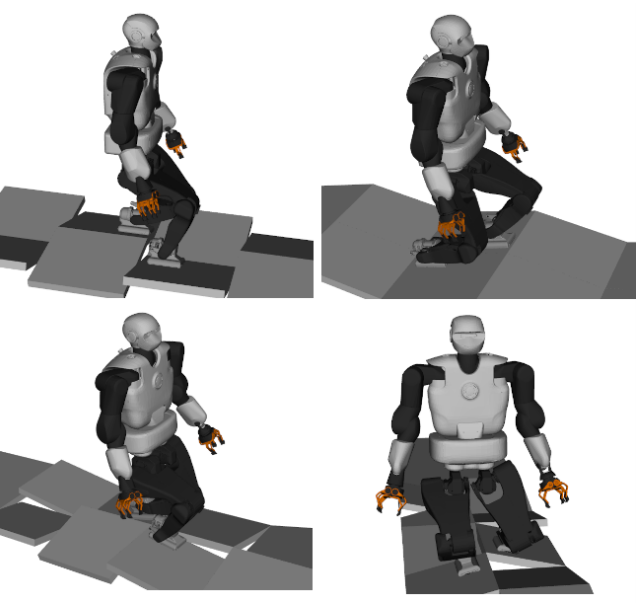
In Receding Horizon Planning (RHP), it is critical that the motion being executed facilitates the completion of the task, e.g. build momentum to traverse large slopes. This requires a value function that can inform the desirability of robot states. However, given the complex dynamics, value functions are often approximated by expensive computation of trajectories in an extended planning horizon. In this work, to achieve online RHP of multi-contact motions, we propose to learn an oracle that can predict local objectives as intermediate goals for a given task, based on the current robot state and the environment. These local objectives are used to construct local value functions to guide a short-horizon RHP. To enable generalization across environments, we use a novel robot-centric representation of oracle variables. We also present an incremental training scheme, that can improve the prediction accuracy by adding demonstrations on how to recover from failures. We compare our approach against the baseline (long- horizon RHP) for planning centroidal trajectories of humanoid walking on moderate slopes, as well as large slopes where static stability cannot be achieved. We validate these trajectories by tracking them via a whole-body inverse dynamics controller in simulation. We show that our approach can achieve online RHP for 95%-98.6% cycles, outperforming the baseline (8%-51.2%